Abstract
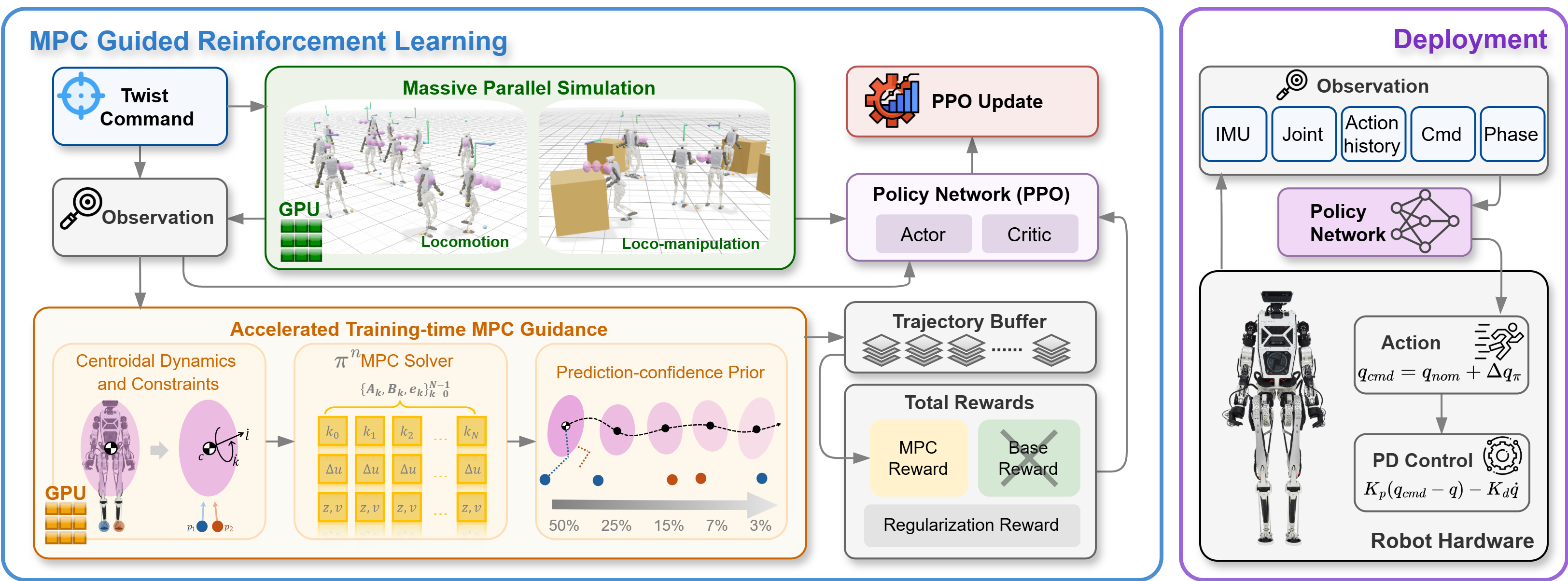
In humanoid motion control, model predictive control (MPC) offers physically grounded prediction and constraint handling, while reinforcement learning (RL) enables robust whole-body skills through large-scale simulation. However, using MPC inside RL often requires time-consuming problem construction or excessive training overhead, making such frameworks difficult to justify in practice. This work studies efficient training-time MPC guidance for humanoid locomotion and manipulation, termed MPC-RL. We introduce a centroidal-dynamics MPC reward formulation that leverages guidance from MPC trajectories in training time. To make this practical in massively parallel RL, we develop πⁿMPC, a parallel-in-horizon and construction-free batched GPU MPC solver that operates directly on time-varying dynamics to avoid high memory usage and pre-compilation. Through a variety of comparative studies and hardware validations, we have found that MPC-RL achieves superior performance in locomotion and manipulation skills.
System Architecture
Video Gallery
Humanoid Locomotion
Push Recovery
Cart Pushing Manipulation
Cart Pushing Manipulation
Payload Carrying
Payload Carrying
BibTeX
@article{li2026mpcrl,
title={Accelerating and Scaling MPC-Guided Reinforcement Learning for Humanoid Locomotion and Manipulation},
author={Li, Junheng and Wu, Liang and Esteban, Sergio A. and Yang, Lizhi and Drgo\v{n}a, J\'an and Ames, Aaron D.},
journal={arXiv preprint arXiv:2606.05687},
year={2026},
}